用户反馈Spark Thrift Server每隔一段时间就会内存溢出,一般来说Spark driver内存溢出就是执行某SQL查询且没有添加limit,导致返回超大数据量,但是提供给客户的即席查询工具会自动添加limit语句,怎么会内存溢出呢。。。
先看看客户环境再说,客户环境已经生成了heap dump文件,文件超大90多G,也不晓得能否用eclipse mat分析,根据以往经验mat内存不能打开比自己大。会不会mat升级了,解决了这个问题呢,抱着试试看的态度,重新下载最新版MemoryAnalyzer-1.13.0 linux版本。
mat 1.13需要jdk11以上,修改MemoryAnalyzer.ini文件增加jdk路径,同时调整heap参数,本机内存20G,给mat分配16G试试,使用mat打开文件,吃完饭回来看结果。
-vmusr/java/jdk-17.0.5/bin/-Xms16384m-Xmx16384m居然打开了。。。溢出原因一目了然,下面硬核解析mat图表怎么看。。。
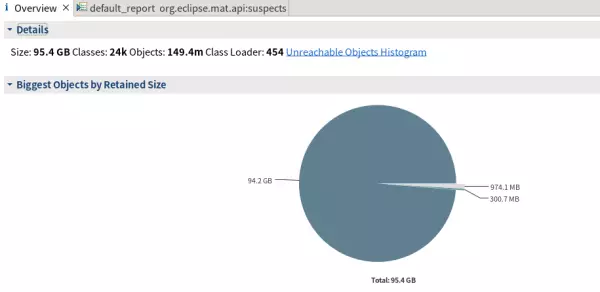
在总览页可以看到最大一个对象占用了94.2GB内存,继续看
打开内存泄漏图,可以看到这个对象是一个Object[]数组,数组来源SparkPlan.executeCollect()
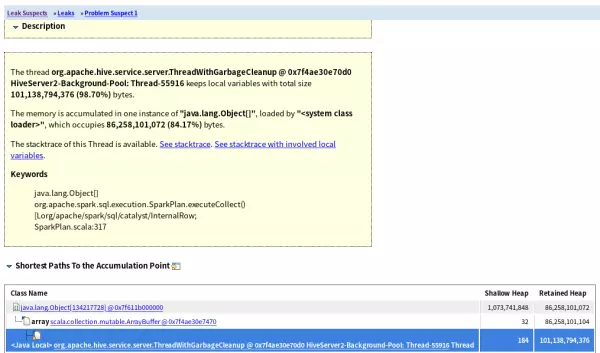
查看线程调用关系,溢出的原因仍然是driver获取返回的数据,说明用户执行了大查询
打开Spark源码核对,SparkPlan.executeCollect()方法内确实定义了一个ArrayBuffer,该类里面就是刚刚的Object[]数组,数组的内容即是表的一行行数据
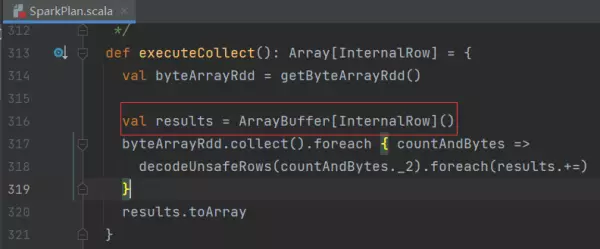
用户执行了什么语句导致内存泄漏呢。。。强大的mat依然可以找到。从thread引用的GC ROOTS对象找,发现和sql相关的SparkExecutionStatementOperation,sql语句就在里面了