在Linux平台上,大家都很熟悉如下经典的Hello world程序 - hello.c。
//File Name: hello.c//The hello world program#includestdio.hintmain(){printf("hello, world");return0;}问题:
- 现代的操作系统都支持虚拟内存机制,那hello world程序的虚拟地址空间是如何布局的?
或者面试官:
- 介绍一下hello world程序的虚拟地址空间。
- 介绍一下Linux C/C++程序的地址空间的布局。
每个高级语言源程序经编译、汇编、链接等处理生成可执行的二进制机器目标代码时,都被映射到一个统一的虚拟地址空间。以x86-64平台为例,下图是Linux上一个进程的虚拟地址空间映像。
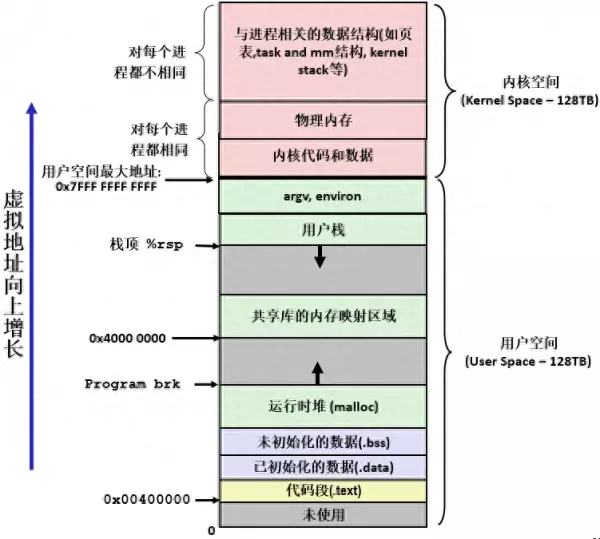
x86-64平台Linux系统进程虚拟地址空间
所谓“统一”是指不同的可执行文件所映射的虚拟地址空间大小一样,地址空间中的区域划分结构也相同。所有进程的虚拟地址空间大小和结构一致,一方面简化了链接器的设计和实现,另一方面也简化了程序的加载过程。
当可执行文件执行时,Linux操作系统会创建一个进程来运行可执行程序,Linux系统为每个应用程序提供了一个私有的虚拟地址空间,使得程序员以为自己的程序在执行过程中独占拥有存储器,这个私有地址空间就是虚拟地址空间。虚拟地址空间分为两大部分:
• 内核虚拟地址空间,简称为内核空间
• 用户虚拟地址空间,简称为用户空间
无论在IA-32平台上,还是x86-64上,进程虚拟空间的概念都是类似的,主要的不同在于地址空间的大小及各区域的地址分布不同。
1) 内核空间
内核空间用来映射到操作系统内核代码和数据、物理内存,以及与每个进程相关的系统级上下文数据结构,其中内核代码和数据区在每个进程的地址空间中都相同。用户程序没有权限访问内核空间,如果用户程序试图访问内核空间的地址,这将会导致用户程序异常,典型的会产生段错误而导致程序死机。
2) 用户空间
用户空间用来映射到用户进程的代码、数据、堆和栈等用户级上下文信息。用户空间又被分为以下几个区域:
•文本段,也称为代码段
代码段包含了在CPU上执行的程序的机器指令 和常量数据,典型的函数都会放到代码段中。代码段通常是只读的,主要是为了防止进程可能通过错误的指针值意外的修改了代码段。代码段是可执行和可共享的,许多进程可以运行相同的程序,并且可以映射到所有进程的虚拟地址空间中。对于频繁执行的程序来说,在内存中只需有一份代码即可。代码段和数据段直接从可执行目标文件的内容来初始化。
•数据段。
可读可写数据区。 典型的,数据段映射了ELF文件中的.data section和.bss section,这些
section是可读写的,但不可执行。
•堆区(heap)
堆是一个在运行时可以动态分配内存的区域,例如,C语言中用malloc函数分配的存储区,或C++中用new操作符分配的存储区。申请一块内存时,动态地从低地址向高地址增长,可用free函数或 delete操作符释放相应的一块内存区。在历史上,堆被放置在未初始化数据和堆栈之间。堆的顶端被称为程序断点。堆内存一般由程序员分配和释放,如果程序员不释放在堆中动态分配的内存,可能会造成内存泄漏。当然,在程序结束时,即便在堆中分配的内存没有释放,也会被操作系统回收。
•共享库
用来存放公共的共享函数库代码。如libc.so。
•栈
在用户虚拟地址空间的顶部是用户栈,用来存放程序运行时过程调用的参数、返回地址、过程局部变量等。随着程序的执行,该区会不断动态地从高地址向低地址增长或向反方向减退。特别地,每次调用函数时,栈会增长。每次从函数返回时,它会缩小。每次调用函数时,系统都会为被调用的函数分配一个栈帧,函数的局部变量、参数、返回地址以及调用者环境的某些信息(如一些保存寄存器)都会保存在栈帧上。
每个区域都有相应的起始位置,堆区和栈区相向生长,栈区从内核起始位置开始向低地址增长,栈区和堆区合起来称为堆栈,其中的共享库映射区从0x40000000开始向高地址增长。只读代码区从0x8048000或0x400000开始向高地址增长。
从本质上来看,程序主要由2部分组成:
• 代码
• 数据
代码存储在代码段中,数据根据类型的不同存储在不同的区域中。数据可以被代码读取、修改和输出,以实现程序的功能。代码是程序执行的指令集合,它告诉计算机要执行哪些操作,包括算术运算、逻辑运算、条件判断、函数调用等等。
数据根据类型的不同存储在不同的区域中:
• 全局数据(变量)和静态数据(变量)有可能在整个程序执行过程中都需要访问,因此单独存储管理。
• 栈区存储的数据主要用于实现函数调用,包括函数的非静态局部变量、函数参数和返回地址等,生命周期短。
• 堆区由程序员按需分配,自行管理。
之所以分成这么多个区域,主要基于安全和效率等方面的考虑:
• 代码段通常是只读的,通常在程序执行时不会被修改。这样做可以提高程序的安全性和运行效率,防止程序意外修改代码。
• 数据段用于存储程序中的全局变量和静态变量,它是可读可写的。典型的,数据段映射了ELF文件中的.data section和.bss section。
• 栈(stack)是实现函数调用所必须的段,主要用于存储函数调用过程中的非静态局部变量、参数和返回地址等信息。程序可以通过栈来方便地管理函数调用和返回过程。栈的大小会在程序运行时动态调整。
- 堆(heap)用于存储程序运行时由程序员动态分配的内存,由程序员自行管理。例如使用malloc()/new分配的内存。堆的大小可以根据程序运行时的需要进行动态调整。
总结:
通过本文的学习,我们了解了如下内容:
1) Hello world程序或Linux C/C++程序的虚拟地址空间以及各空间区域的用途。
2) 深刻的理解程序的地址空间,对理解进程、程序的本质和调试都有非常大的帮助。