在高级编程语言中,大多含有一个指令叫return,也就是程序的执行指令流遇到该语句后不再往下执行,而是返回上一层,如果return后面附带数据的话,程序会把数据夹带到调用栈上一层的代码执行路径。本节我们就给Monkey语言编译器增加解释执行return语句的功能,完成本节代码后,编译器能解释执行如下代码:
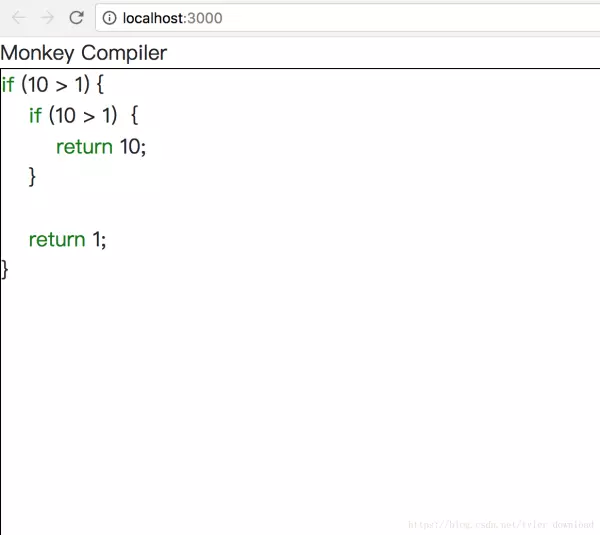
代码中存在两个if 间套,内层if执行return语句附带返回整数10,外层if 最后执行return语句附带放回数值1,根据代码逻辑,最后一条语句也就是return 1;不会被编译器所执行,编译器会把内层if里面的return语句执行后,把整形10返回给最外层,完成本节代码后,编译器对上面代码解释执行的结果如下:
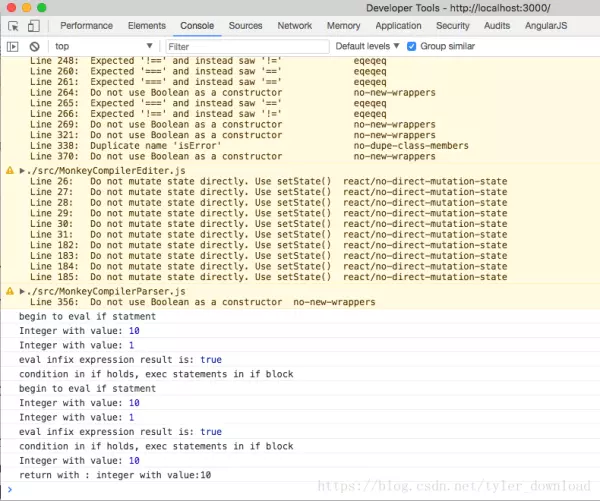
从运行结果看,编译器解释执行了一系列if条件判断语句后,将内层if语句块包含的return语句执行了,并没有执行外层if语句块包含的return语句,所以在控制台输出上显示出编译器将数值10返回给最外层。接下来我们看看代码的实现。
我们现在代码中添加return 返回值对应的符号对象:
//change 1class ReturnValues extends BaseObject { constructor { super this.valueObject = props.value } type { return this.RETURN_VALUE_OBJECT } inspect { this.msg = "return with : " + this.valueObject.inspect return this.msg }}上面实现的符号对象,主要功能就是把return后面的数值或变量包裹在类ReturnValues中。接着我们在解释执行的主函数中添加对return语句的专门处理分支:
class MonkeyEvaluator { eval { var props = {} switch { ... //change 2 case "ReturnStatement": var props = {} props.value = this.eval // change 12 if ) { return props.value } var obj = new ReturnValues console.log) return obj ... } ...}当语法解析器解析到return语句时,会构造一个类型为”RetturnStatement”的语法树节点,我们在解释执行函数中,如果发现该节点被传入,那么就进入对应执行分支。在return语句后面很可能是一个复杂的运算表达式,所以代码先递归调用eval解释执行return后面的语句以便获得要返回的数据对象,接着把该数据对象封装在前面设计的ReturnValues符号对象里。
在上一节,我们增加了一个函数evalStatements用来解释执行if语句块,其内容如下:
evalStatements { var result = null for { result = this.eval if == result.RETURN_VALUE_OBJECT || result.type == result.ERROR_OBJ) { // change 3 return result } } return result }使用上面的函数去解释本文最开始给出的if间套语句会有问题,因为上面代码的执行方式是把if语句块里面的每条代码都解释执行一遍,然后把最后一条语句解释执行的结果返回给上一层,这样的话编译器在解释执行开头给出的代码时,它会解释执行最外层if语句块最后一条语句后才停止,于是使用上面代码解释执行if语句块就会造成错误,因为根据逻辑,语句“return 1;”是不应该被执行的。我们要修改代码处理这个问题,在MonkeyCompilerIDE.js中修改代码如下:
onLexingClick { this.lexer = new MonkeyLexer this.parser = new MonkeyCompilerParser this.parser.parseProgram this.program = this.parser.program /* for { console.log this.evaluator.eval } */ // change 4 this.evaluator.eval }我们把语法解析后形成的语法树根节点,也就是Program对象直接传入解释器的eval函数,在MonkeyCompilerParser.js中也做一些相应修改:
class Program { constructor { this.statements = // change 3 this.type = "program" } getLiteral { if { return this.statements.tokenLiteral } else { return "" } }}回到MonkeyEvaluator.js中,我们在eval函数中添加对应处理代码:
eval { var props = {} switch { //change 5 case "program": return this.evalProgram ... } ...}.... //change 5 // change 3 in MonkeyCompilerParser.js // change 4 in MonkeyCompilerIDE.js evalProgram { var result = null for { result = this.eval if == result.RETURN_VALUE_OBJECT) { return result.valueObject } if == result.NULL_OBJ) { return result } // change 10 if { console.log return result } } return result }完成上面代码之后,编译器就能正确的解释执行return语句了,更详细的讲解和代码调试演示,请参看上头给出的视频链接。接下来我们要为编译器添加错误处理信息。所谓错误处理是指用户在编程时,使用了错误的数理逻辑,例如下面这样:
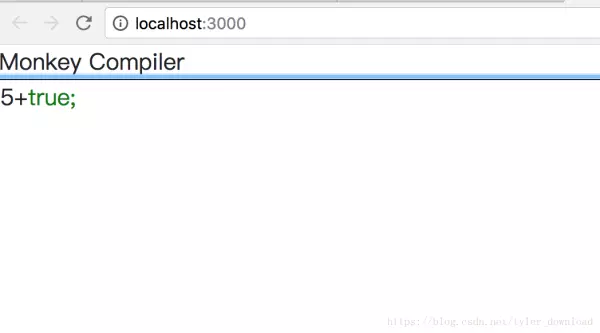
上述代码把一个整形和一个布尔型数据相加,这在逻辑上走不通,因此在编译器看来是一种逻辑错误,当出现这种错误是,编译器就得报错,并停止继续往下执行代码。编译器报错情况如下:
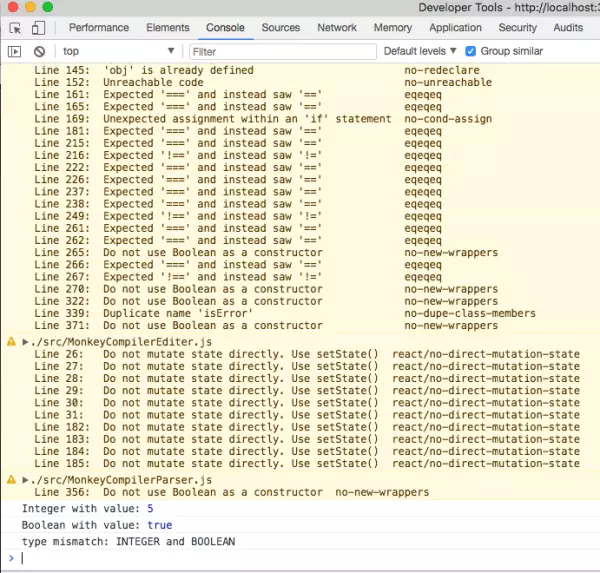
接下来我们就为此添加错误处理功能,在MonkeyEvaluator.js中添加如下代码:
// change 6 newError { var props = {} props.errMsg = msg return new Error }msg表示的是错误消息字符串,上面函数把它封装到一个名为Error的符号对象里,我们看看其定义实现:
class Error extends BaseObject { constructor { super this.msg = props.errMsg } type { return this.ERROR_OBJ } inspect { return this.msg }}错误符号对象原理很简单,它就是封装了一条错误信息字符串msg以便给编译器在合适的时候显示出来。接着我们在合适的地方检测类型匹配错误,首先是在解释执行中序表达式时,添加代码如下:
evalInfixExpression { //change 7 if != right.type) { return this.newError } ...//change 8 return this.newError}前面例子中出错的语句”5+true”就是中序表达式,该函数在解释执行表达式前,先检测运算符两边的数据类型是否一致,如果不一致的话,调用newError函数构造一个Error对象后直接返回,不再继续往下执行。或者在中序表达式中,编译器遇到了识别不了的运算符,那么它也会构造一个错误对象返回。
如果代码在对两个整形数据进行运算时,使用了编译器无法识别的运算符,那么编译器也会构造一个错误对象返回:
evalIntegerInfixExpression { .... switch { .... default: // change 9 return this.newError } ....}在取负操作时,如果减号后面跟着的不是整形,那么编译器也报错,例如”-true”,这种代码是错误的,因此修改如下:
evalMinusPrefixOperatorExpression { if !== right.INTEGER_OBJ) { // change 8 return new this.newError) } ....}在evalProgram函数中,它会把所有子节点就像解释执行,但如果在执行中间遇到错误时,那么就必须终止执行流程,于是在该函数中也要进行相应修改:
evalProgram { var result = null for { ... // change 10 if { console.log return result }}我们添加一个函数用于判断,eval函数在解释执行对应的语法树节点后,返回的是否是一个错误对象:
// change 11 isError { if { return obj.type == obj.ERROR_OBJ } return false }在不少地方,例如return后面的表达式,if括号里面的条件判断表达式,他们在解释执行时都可能产生错误,因此我们需要在相应的位置进行监控:
eval{ .... switch { .... case "PrefixExpression": ... // change 13 if ) { return right } ... case "InfixExpression": var left = this.eval // change 14 if ) { return left } var right = this.eval //change 15 if ) { return right } case "ReturnStatement": .... // change 12 if ) { return props.value } .... }上面代码在处理return语句时,检测return后面跟着的表达式被编译器解释执行后是否出错,如果出错则把错误对象返回。在解释执行前置表达式时,编译器检测运算符后面的表达式在解释执行时是否正常,如果出错则直接将错误返回。
接下来则是在if语句的解释执行部分进行错误检测:
evalIfExpression { console.log var condition = this.eval // change 16 if ) { return condition } ....}代码在执行if语句块前,先判断if括号里的条件表达式在解释执行时是否正常,如果有错就不再往下执行,完成上面代码后,编译器就基本建立了语法上的错误检测机制。